Previous slide Next slide Toggle fullscreen Open presenter view
Harnessing AWS Bedrock & Langchain for Advanced Chatbots
Intro
IpponGPT
Leverages a serverless LLM service via AWS Bedrock (Anthropic Claude )
Built using the Langchain framework to combine various components (DB, memory, routers, etc)
Utilizes AWS OpenSearch Serverless as a Vector DB
Relies on the Slack Bolt framework for the Slack integration via Websockets
Agenda
Overview of Bedrock
Embeddings & Vector Databases
Overview of Langchain
Demo
What is AWS Bedrock
Managed LLM service focused on ease of use
Provides access many Foundational Models (Claude, Command, Mistral, Llama )
Tightly integrated with other services (Knowledge Bases for Bedrock)
Finetunning vs Knowledge Base
Finetunning LLM -> Change LLM behaviour
Knowledge Base -> Gain domain knowledge
Retrieval Augmented Generation (RAG)
This is the usecase Knowledge Bases for Bedrock is tyring to solve
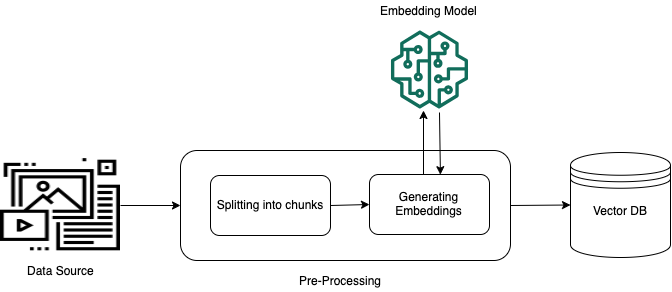
Preprocessing Step
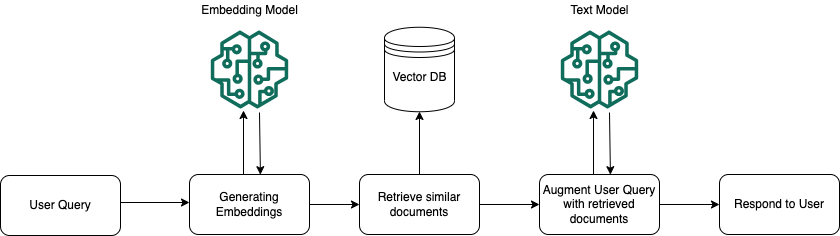
Retrieval Step
Preprocessing Step
Retrieval Step
What is an embedding?
What is a vector database?
Designed to store and retrieve data based on similarity
Dedicated Vector DB: Pinecone, Chroma, LanceDB
Supports Vector Search: OpenSearch, Postgres, Cassandra
How are vectors stored?
┌────────────────────────────────────────────────────────┐
│ ┌─────────┐ │
│ ┌────────┐ │ Doc │ │
│ │ Doc │ └─────────┘ │
│ └────────┘ ┌──────────┐ │
│ ┌──────────┐│ Doc │ │
│ │ Doc │└──────────┘ │
│ └──────────┘ │
│ │
│ │
│ ┌───────┐ │
│ │ Doc │ │
│ └───────┘ │
└────────────────────────────────────────────────────────┘
in this simple vector database, documents in the upper right corner are more closely related
What is Langchain
Open-source framework for building LLM powered apps
Model agnostic, bring your own LLM (milage may vary)
Large and growing community supporting 3rd party integrations
Part of a larger ecosystem: LangSmith, LangServe, LangGraph
Enables easily stitching prebuilt components into 'chains'
What is Langchain Cont'd
Set of high-level abstractions around core components
Components can be linked together to form chains
Allows for flexibility when changing LLMs, Vector DBs, etc
Uses LangChain Expression Language (LCEL) to define chains -> similar to pipe operator |
Preprocessing code example
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import S3FileLoader
from langchain_community.vectorstores.opensearch_vector_search import (
OpenSearchVectorSearch,
)
def save_documents (index, docs ):
return OpenSearchVectorSearch.from_documents(
documents=docs, embedding=get_openai_embeddings(), **get_vectorstore_args(index)
)
loader = S3FileLoader(S3_BUCKET, EMP_HANDBOOK_KEY)
docs = loader.load()
chunk_size, chunk_overlap = calculate_chunks(docs)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len ,
is_separator_regex=False ,
)
splits = text_splitter.split_documents(docs)
save_documents("employee-handbook" , splits)
Retrieval code example
from langchain.chains import RetrievalQA
from langchain_core.prompts import PromptTemplate
from langchain_community.chat_models import BedrockChat
from langchain_community.vectorstores.opensearch_vector_search import (
OpenSearchVectorSearch,
)
def get_vectorstore (index ):
return OpenSearchVectorSearch(
embedding_function=get_openai_embeddings(), **get_vectorstore_args(index)
)
llm = BedrockChat(
client=get_bedrock_client(),
model_id=CLAUDE_MODEL,
model_kwargs={"temperature" : 0 },
)
emp_handbook_retriever = get_vectorstore("employee-handbook" ).as_retriever(
search_type="similarity" , search_kwargs={"k" : 4 }
)
employee_handbook_chain = RetrievalQA.from_llm(
retriever=emp_handbook_retriever,
prompt=PromptTemplate.from_template(PROMPT_HANDBOOK),
llm=llm,
return_source_documents=True ,
)
employee_handbook_chain.invoke("question" : "what is the leave policy?" )
Prompting Techniques
Zero-Shot Prompt: Instructs the model to perform a task
Few-Shot Prompt: Includes a examples, samples, or snippets with desired output
Chain of Thought: Instructs the model to explain their reasoning
More techniques at Prompt Engineering Guide
Chain example using LCEL
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
topic_chain = (
{"question" : RunnablePassthrough()}
| PromptTemplate.from_template(PROMPT_ROUTE)
| llm
| StrOutputParser()
)
topic_chain.invoke({"question" : "what is the leave policy?" })
What else can we do with Langchain
Routing between mulitple chains
Nesting chains
Including chat history
Rephrasing queries based on context and history
And much much more...
Routing between multiple chains
from langchain_core.runnables import RunnableBranch
branch = RunnableBranch(
(
lambda x: x["topic" ] == "RESUMES_AND_ORG_CHART" ,
RetrievalQA.from_llm(PROMPT_RESUMES, resume_retriever)
),
(
lambda x: x["topic" ].strip() == "HANDBOOK" ,
RetrievalQA.from_llm(PROMPT_BENEFITS_AND_POLICIES, benefits_retriever)
),
(
lambda x: x["topic" ].strip() == "CASE_STUDIES" ,
RetrievalQA.from_llm(PROMPT_CASE_STUDIES, case_studies_retriever)
),
general_chain,
)
Nesting multiple chains together
topic_chain = (
{"question" : RunnablePassthrough()}
| PromptTemplate.from_template(PROMPT_ROUTE)
| self.llm
| StrOutputParser()
)
full_chain = {
"topic" : topic_chain,
"question" : itemgetter("question" )
} | branch
full_chain.invoke({"question" : "what is the leave policy?" })
Including chat history
from service.in_memory import ChatWindowMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
def get_session_history (self, session_id: str ) -> BaseChatMessageHistory:
if session_id not in self.store:
self.store[session_id] = ChatWindowMessageHistory(k=10 )
return self.store[session_id]
with_history = RunnableWithMessageHistory(
chain,
self.get_session_history,
input_messages_key="question" ,
history_messages_key="history" ,
)
Rephrasing questions based on contexnt
prompt = PromptTemplate.from_template(PROMPT_REPHRASE)
rephrased_chain = (
{
"question" : itemgetter("question" ),
"history" : itemgetter("history" ),
}
| prompt
| llm
| StrOutputParser()
)
chain = {"question" : rephrased_chain} | full_chain
chain.invoke({"question" : "what is the leave policy?" })
What's the flow for IpponGPT?
Architecture Diagram
Where do you go from here
Try other prompting techniques -> Few-Shot Prompting
Cache answers for related questions
Try LLM finetunning with your own data
Include a manual feedback mechanism for answers
Where to save on cost
Use an LLM Router based on user input
Reduce tokens by removing compressing prompts -> LLMLingua
Start with smaller models
I'm here to talk about IpponGPT, what it is and how we built it.
I can talk you about IpponGPT, a Bedrock + Langchain powered chatbot
in our internal slack.
* Focused around providing a friendly experience
* Offers multiple pretrained LLMs for specific uses
Lets step back for a second to talk Finetunning VS Knowledge Base
https://www.emojisearch.app/
https://til.simonwillison.net/tils?
How do we go about:
- Creating those embeds
- Accessing them
How do start putting these components together?