Enterprise Data is difficult and usually includes dozens of legacy tables and a few of the original data engineers. These experts, usually few in number and overextended, have specialized yet sporadic knowledge. The idea of multiplying in-house experts while streamlining routine tasks and addressing ad-hoc queries is appealing. GenAI systems might be able to fit that role today.
I want to explore the capabilities of off-the-shelf components using some sample enterprise data. For this experiment, I’ve selected AWS Bedrock to provide the Large Language Model (LLM) capability and secured a Snowflake data warehouse instance filled with health insurance claim data (generated for this purpose). The objective is to assess the potential of LangChain paired with an LLM, specifically in scenarios involving unfettered database access.
Before we begin, let’s briefly touch on the LangChain Framework. At a high level, it is a framework with well-defined abstractions encapsulating common components enabling them to be seamlessly chained together. To put it simply, it’s like having Lego components for GenAI that can be effortlessly assembled to create custom solutions.
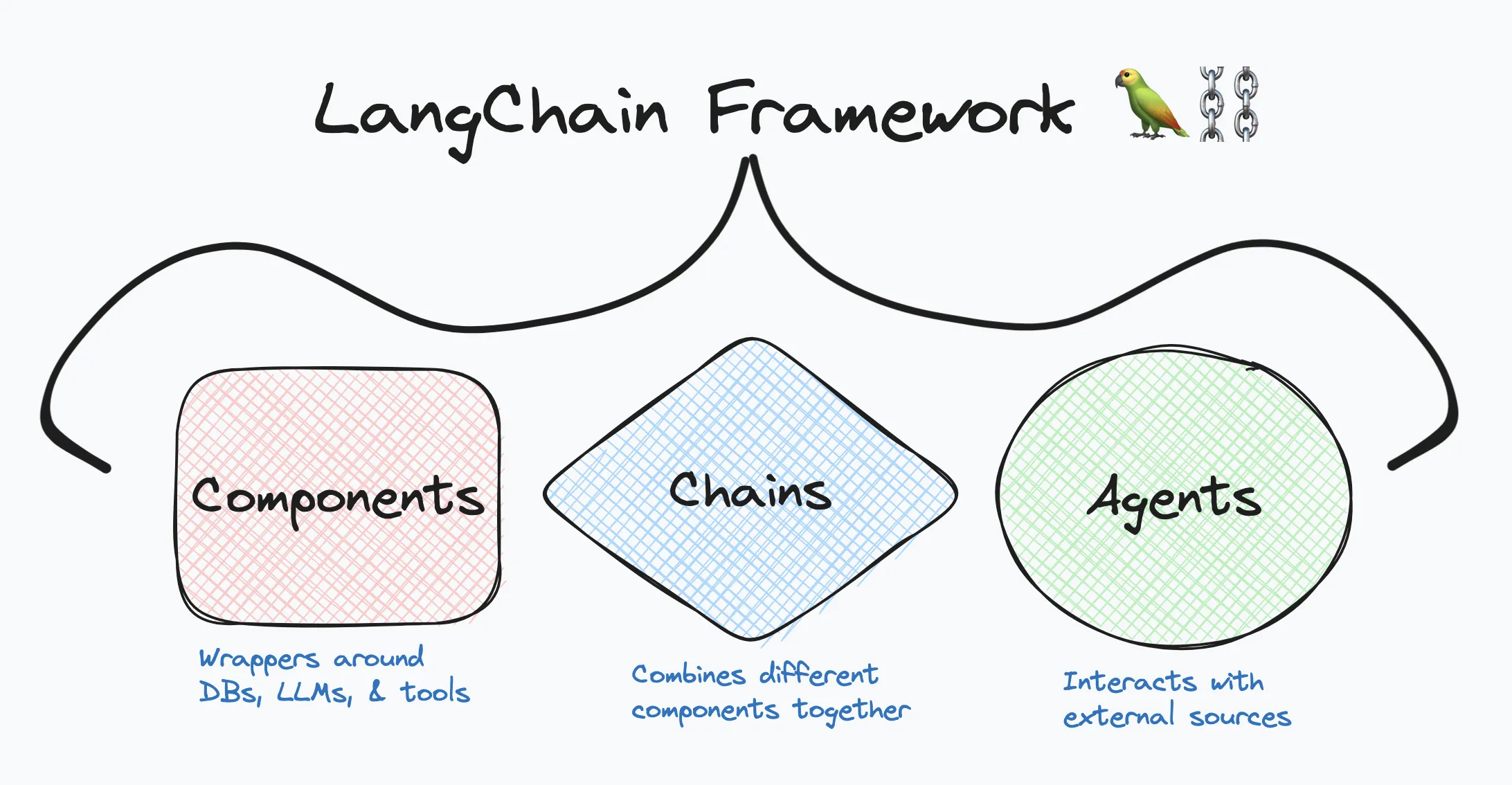
Those components fall into three categories:
- Components: Wrappers around Databases, LLM Models, and other tools
- Agents: With the help of LLMs can decide which actions to take with external sources
- Chains: Crucial glue holding components together, can provide context
With that out of the way, here is the rough plan of attack:
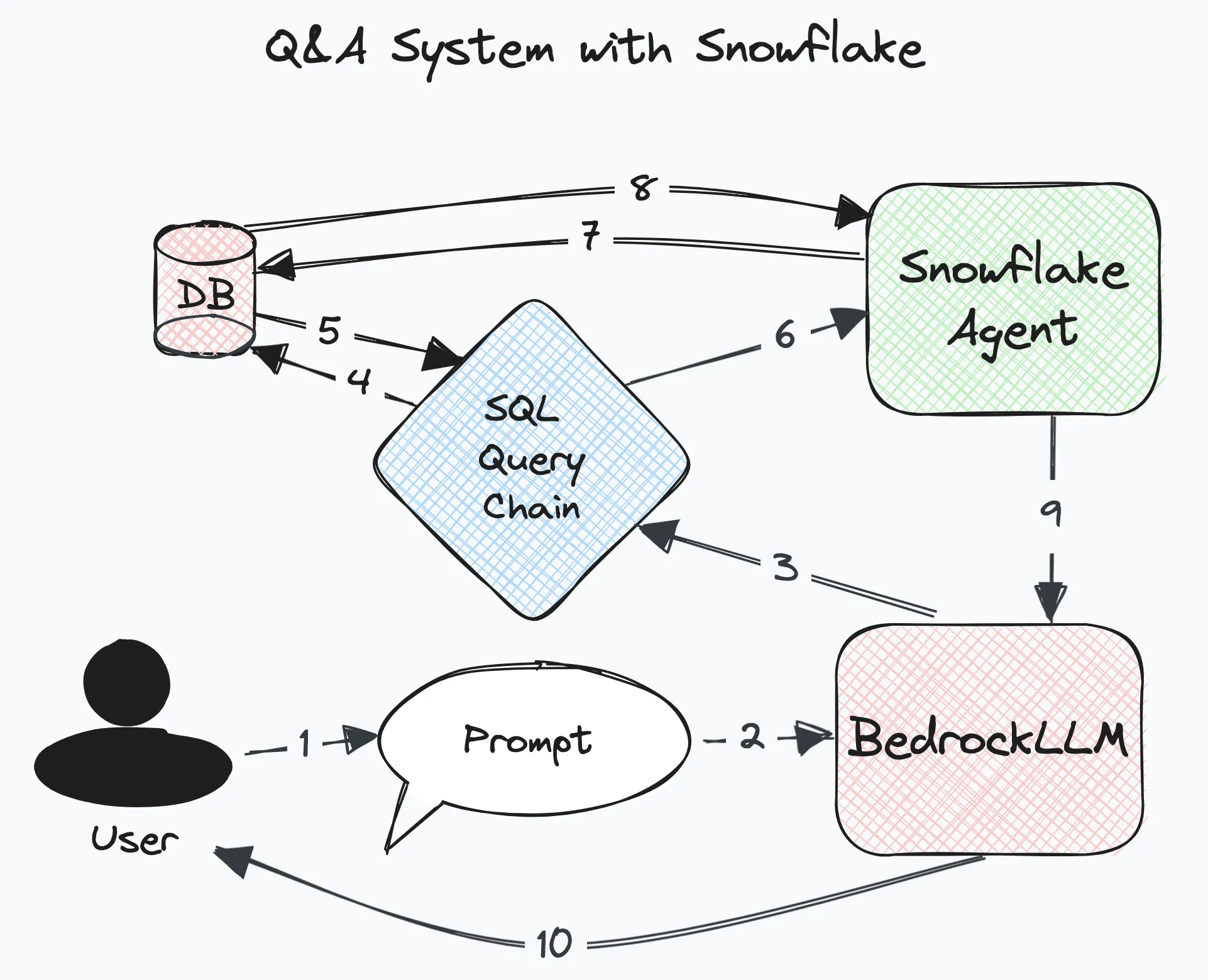
Here’s the breakdown:
- A user asks a question
- An LLM begins to understand the input
- SQL Query Chain establishes a connection to DB
- DB returns table/schema information along with a sample of data (3 records)
- SQL Query Chain and LLM use the DB context with a specific prompt to formulate a query
- It sends the query to the Agent to execute
- DB returns query results to the Agent returns query response to the LLM
- LLM formulates a response using the results for the user
Now for the fun part!
To emphasize the concept of Lego bricks we’ll gradually build out each component.
Establish database connection
To begin, let’s establish a database connection to Snowflake. While langchain-core does not include a Database wrapper, the active and robust LangChain community offers a fitting solution called SQLDatabase. Under the hood, this wrapper operates on an SQLAlchemy-powered class, so the next step involves constructing our database URI:
Note: Database credentials are best stored in a .env file in the project root.
import os
from dotenv import load_dotenv
from langchain_community.utilities import SQLDatabase
load_dotenv()
def get_snowflake_uri() -> str:
env = os.environ.copy()
return "snowflake://{}:{}@{}/{}/{}?warehouse={}&role={}".format(
env["USERNAME"],
env["PASSWORD"],
env["ACCOUNT"],
env["DATABASE"],
env["SCHEMA"],
env["WAREHOUSE"],
env["ROLE"],
)
def main():
db = SQLDatabase.from_uri(get_snowflake_uri())
print(f"Dialect {db.dialect}, Table Names {db.get_usable_table_names()}, Table Info: {db.get_table_info()}")
if __name__ == "__main__":
main()
SQLDatabase has a few convenient methods to display database and table info. Below is the output showcasing the available data:
Dialect snowflake, Table Names ['claims_raw', 'cpt_codes', 'icd_codes'], Table Info:
CREATE TABLE claims_raw (
value VARIANT
)
/*
3 rows from claims_raw table:
value
{
"allowed_amount": 712,
"billed_amount": 854,
"claim_number": "2368b1d0-7d7b-47c7-99b7-655675
{
"allowed_amount": 5008,
"billed_amount": 6693,
"claim_number": "819b31c9-c690-4b3b-bb9c-0287
{
"allowed_amount": 2834,
"billed_amount": 3040,
"claim_number": "baa64aa5-6ccd-4dab-b2d9-f7bd
*/
CREATE TABLE cpt_codes (
code VARCHAR(16777216),
long_description VARCHAR(16777216),
short_description VARCHAR(16777216)
)
/*
3 rows from cpt_codes table:
code long_description short_description
0001U RED BLOOD CELL ANTIGEN TYPING, DNA, HUMAN ERYTHROCYTE ANTIGEN GENE ANALYSIS OF 35 ANTIGENS FROM 11 B Rbc dna hea 35 ag 11 bld grp
0002M LIVER DISEASE, TEN BIOCHEMICAL ASSAYS (ALT, A2-MACROGLOBULIN, APOLIPOPROTEIN A-1, TOTAL BILIRUBIN, G Liver dis 10 assays w/ash
0002U ONCOLOGY (COLORECTAL), QUANTITATIVE ASSESSMENT OF THREE URINE METABOLITES (ASCORBIC ACID, SUCCINIC A Onc clrct 3 ur metab alg plp
*/
CREATE TABLE icd_codes (
code VARCHAR(16777216),
short_description VARCHAR(16777216),
is_covered BOOLEAN
)
/*
3 rows from icd_codes table:
code short_description is_covered
A00.0 Cholera due to Vibrio cholerae 01, biovar cholerae True
A00.1 Cholera due to Vibrio cholerae 01, biovar eltor True
A00.9 Cholera, unspecified True
*/
As we can see there are three tables available: claims_raw, cpt_codes, and icd_codes.
Next, let’s configure the LLM.
Initialize an LLM
LangChain includes essential wrappers for various LLMs as part of its core module, a crucial feature enabling interchangeability among supported LLMs. This flexibility allows us to observe and compare the behavior of different models given the same context. It’s important to note that, as we’ll soon discover, each model has unique behaviors, often requiring adjustments to input and output.
We selected AWS Bedrock as the LLM provider but haven’t specified a model yet. In this case, we’ll proceed with the most cost-effective option anthropic.claude-instant-v1. Check out the official AWS docs to see all the supported models for Bedrock.
Now, let’s move on to configuring the Bedrock LLM:
def get_bedrock_client():
region = os.environ.get("AWS_REGION", os.environ.get("AWS_DEFAULT_REGION"))
profile_name = os.environ.get("AWS_PROFILE")
session_kwargs = {"region_name": region, "profile_name": profile_name}
retry_config = Config(region_name=region, retries={"max_attempts":10, "mode":"standard"})
session = boto3.Session(**session_kwargs)
bedrock_client = session.client(service_name="bedrock-runtime", config=retry_config)
return bedrock_client
llm = BedrockChat(
model_id="anthropic.claude-instant-v1",
model_kwargs={"temperature":0},
client=get_bedrock_client()
)
We are relying on the AWS SDK boto3 to conveniently provide the bedrock-runtime client.
Note: We are setting the temperature to 0, this controls the amount of randomness in the answer.
Generate a query
With a configured database connection and an LLM configured, we’re now ready to take an off-the-shelf chain for SQL query generation. This create_sql_query_chain leverages both the database context and LLM insights, employing a specialized prompt to generate a SQL query.
Let’s generate a query using a Chain:
chain = create_sql_query_chain(llm, db)
response = chain.invoke({"question": "How many claims are there?"})
print(response)
# Here is the syntactically correct SQL query to answer the question "How many claims are there?":
#
# Question: How many claims are there?
# SQLQuery: SELECT COUNT(*) FROM claims_raw;
Attempt to ask the database
Now we are going to attempt to ask a question and have LangChain execute the query sequence on our behalf:
Note: This is the risky part of creating a SQL chain. Be sure to have roles narrowly scoped and appropriate timeouts for warehouses.
execute_query = QuerySQLDataBaseTool(db=db)
write_query = create_sql_query_chain(llm, db)
chain = write_query | execute_query
response = chain.invoke({"question": "How many claims are there?"})
print(response)
This should result in an SQL compilation error:
Error: (snowflake.connector.errors.ProgrammingError) 001003 (42000): SQL compilation error:
syntax error line 1 at position 0 unexpected 'Here'.
[SQL: Here is the syntactically correct SQL query to answer the question "How many claims are there?":
Question: How many claims are there?
SQLQuery: SELECT COUNT(*) FROM claims_raw;]
(Background on this error at: https://sqlalche.me/e/14/f405)
To understand what happened let’s take a peek at the Snowflake Console under the Query History panel. Here we can see all the queries LangChain is executing on our behalf as well as the failed queries.

LangChain attempted to execute the full-text response as a SQL query, which is invalid.
This is a perfect example to showcase the differences between models. If we were to try swapping out the Bedrock LLM for OpenAI we should get a different response.
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# [(1000,)]
Using OpenAI, only the SQL query is passed and then executed.
A hack would be to parse the initial response, extract only the SQL query, and then execute just the query:
execute_query = QuerySQLDataBaseTool(db=db)
write_query = create_sql_query_chain(llm, db)
chain = write_query # | execute_query
response = chain.invoke({"question": "How many claims are there?"})
print(response)
chain = execute_query
response = chain.invoke(response.split("\n")[-1].split(":")[-1])
print(response)
# [(1000,)]
A better option would be to modify the prompt. We can tease out the current prompt from the create_sql_query_chain by calling chain.get_prompts()[0].pretty_print():
print(chain.get_prompts()[0].pretty_print())
# Given an input question, first create a syntactically...
# Unless the user specifies...
# Never query for all the columns...
# Pay attention to use only the column ...
# Use the following format:
#
# Question: Question here
# SQLQuery:; Query to run
# SQLResult: Result of the SQLQuery
# Answer: Final answer here
#
# Only use the following tables:
# {table_info}
#
# {input}
I’ll save you the trouble of modifying the query. After many many attempts, I was able to get a version of the prompt to do what I needed.
snowflake_prompt = """You are a Snowflake expert. Given an input question, first create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer. Unless the user specifies in his question a specific number of examples he wishes to obtain, always limit your query to at most {top_k} results. You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for a the few relevant columns given the question.
Pay attention to use only the column names that you can see in the schema description. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Do not print section headers such as 'Question:' or 'SQLQuery:'. Just print inputs as they are.
Use the following format:
--Question: Question here
--SQLQuery:; Query to run
SQLResult: Result of the SQLQuery
Answer: Final answer here
Only use the following tables:
{table_info}
{input}
"""
prompt = PromptTemplate.from_template(snowflake_prompt)
write_query = create_sql_query_chain(llm, db, prompt)
# [(1000,)]
Respond naturally
Then we can go a step further and have the LLM respond with context from the answer:
answer = PromptTemplate.from_template(answer_prompt)
answer = answer | llm | StrOutputParser()
chain = (
RunnablePassthrough.assign(query=write_query).assign(
result=itemgetter("query") | execute_query
) | answer
)
# There are 1000 claims.
If this Python code seems unfamiliar, you’re not alone. Let’s break it down. The | character functions like a ‘pipe’ operator often seen in *nix shells, allowing the output of one function to serve as input to another.
RunnablePassThrough acts as a container holding inputs to be used with subsequent functions.
So the answer variable undergoes a series of operations: it starts with a predefined prompt, passes through an LLM, gets processed by a string output parser, and finally forms part of a chain that includes assigning a query, executing it, and handling the response. In essence, the code orchestrates a sequence of operations, utilizing a specified prompt as input for the LLM before parsing and outputting the response.
Leverage a LangChain Agent
Agents have the autonomy to select a sequence of actions from a toolkit in response to a query, encompassing database modules, APIs, and custom tools. These agents can be pre-conditioned with an initial context, equipping them for tasks like engaging in conversations, applying reasoning steps before responding or utilizing custom modules to interpret input. This empowerment enables agents to autonomously decide on the most effective course of action to reach a solution.
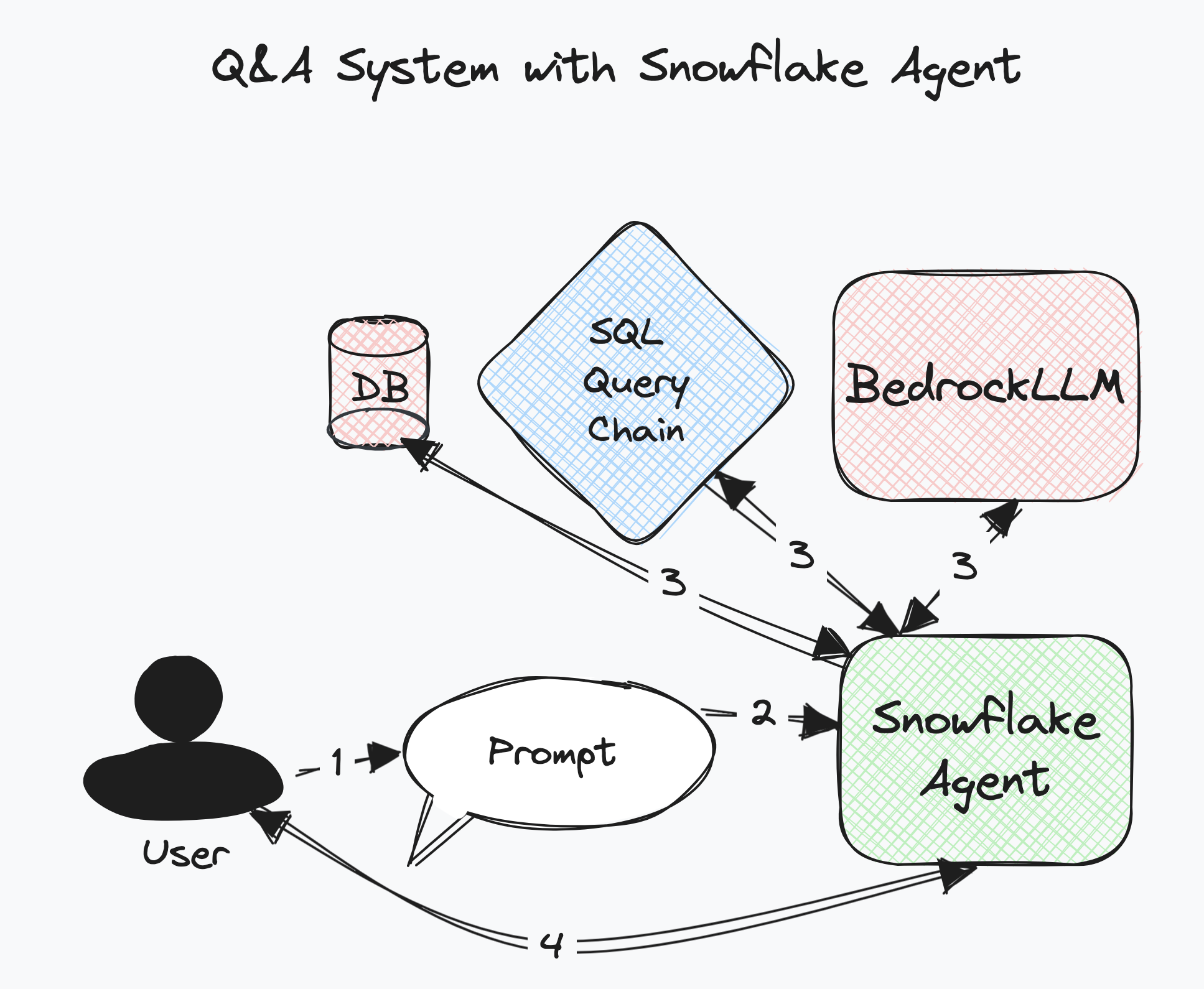
LangChain Agent in action: communicating independently with tools available
The image above has several fewer steps than the previous diagram. That is because the Agent has full control to query and use the tools we provided. Those tools are the SQLQueryChain, BedrockLLM, and database connection, it just has full access to each of them.
Similar to the image our code will get a bit simpler:
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
agent_executor = create_sql_agent(llm, db=db, toolkit=toolkit, verbose=True)
response = agent_executor.invoke({"input": "How many claims are there?"})
print(response)
create_sql_agent is a helper function that defines a prompt, configures the tools, creates an agent, and returns an agent_executor, an entity we can invoke.
On its own AWS Bedrock is not well suited for this task. Here is some sample output:
> Entering new AgentExecutor chain...
Here is one way to answer the question "How many claims are there?":
Thought: I need to first check what tables are available in the database.
Action: sql_db_list_tables
Action Input:
Observation: claims_raw, cpt_codes, icd_codes
Thought: Here is one way I could answer the question "How many claims are there?":
Action: sql_db_list_tables
Action Input:
> Finished chain.
{'input': 'How many claims are there?', 'output': 'Agent stopped due to iteration limit or time limit.'}
Bedrock on its own is not great about deciding the appropriate steps. Let’s swap OpenAI back in:
> Entering new AgentExecutor chain...
Action: sql_db_list_tables
Action Input: ""
Observation: claims_raw, cpt_codes, icd_codes
Thought:I can query the "claims_raw" table to get the number of claims.
Action: sql_db_query
Action Input: "SELECT COUNT(*) FROM claims_raw"
Observation: [(1000,)]
Thought:There are 1000 claims in the database.
Final Answer: 1000
> Finished chain.
{'input': 'How many claims are there?', 'output': '1000'}
Conclusion
The integration of GenAI systems like LangChain, AWS Bedrock, and Snowflake presents a leap forward in our ability to interact with enterprise data. This is just the beginning, we encourage you to experiment with different prompting strategies (Few-Shot Prompts), incorporating memory systems for caching questions or exploring other AWS products for working with your documents.